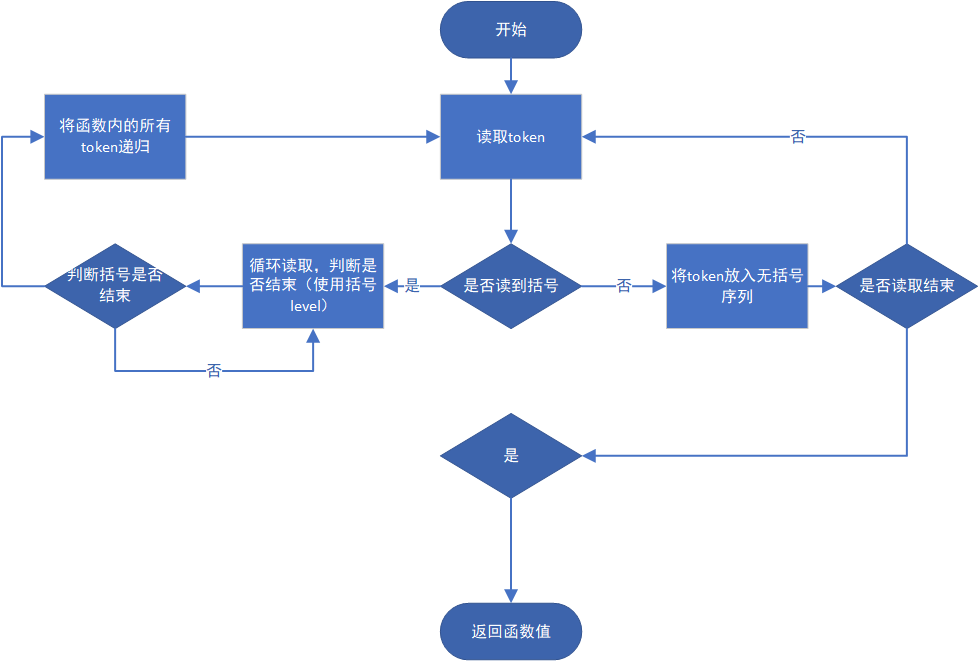
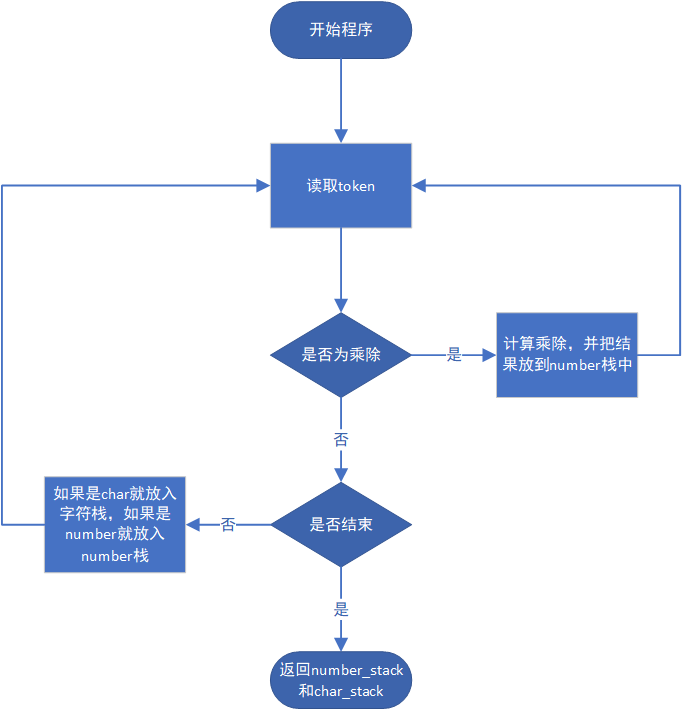
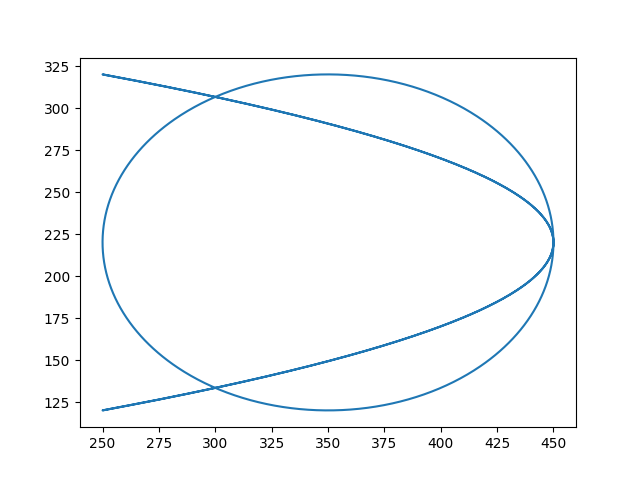
ORIGIn IS (300+25*(1+1), 220); rot is 0; scale is (50, 100); FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(T),sin(T)); scale is (100, 100); FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(2*T),sin(T));
deffor_statement(TOKENS): # 老逼登握拳,大的要来了 global start global step global end global x global y
token: Token token = get_token(TOKENS) if token.tokenType != TokenType.T: print("Error:except 'T' but get", token.tokenType) exit()
token = get_token(TOKENS) if token.tokenType != TokenType.FROM: print("Error:except 'from' but get", token.tokenType) exit()
# 这时就要开始循环读取了遇到逗号时停止读取 flag = False float_tokens = [] while flag isFalse: token = get_token(TOKENS) if token.tokenType == TokenType.TO: # 如果遇到TO就说明结束读入了 flag = True start = get_float(float_tokens) else: float_tokens.append(token)
flag = False float_tokens = [] while flag isFalse: token = get_token(TOKENS) if token.tokenType == TokenType.STEP: # 如果遇到STEP就说明结束读入了 flag = True end = get_float(float_tokens) else: float_tokens.append(token) flag = False float_tokens = [] while flag isFalse: token = get_token(TOKENS) if token.tokenType == TokenType.DRAW: # 如果遇到DRAW就说明结束读入了 flag = True step = get_float(float_tokens) else: float_tokens.append(token)
token = get_token(TOKENS) if token.tokenType != TokenType.L_BRACKET: print("Error:except '(' but get", token.tokenType) exit()
# 到这里我们就得到了之前所有的数据,但是现在我们要开始计算,横坐标和纵坐标的值了 flag = False x_tokens = [] # 用来存储计算x的tokens while flag isFalse: token = get_token(TOKENS) if token.tokenType == TokenType.COMMA: # 如果遇到,就说明结束读入了 flag = True else: x_tokens.append(token)
flag = False y_tokens = [] # 用来存储计算y的tokens while flag isFalse: token = get_token(TOKENS) if token.tokenType == TokenType.SEMICO: # 如果遇到;就说明结束读入了,然后弹出上一个括号 flag = True else: y_tokens.append(token)
y_tokens.pop()
# 现在我们都获得了x和y的计算方式,现在就要开始计算这些东西 # 首先计算x的各种值 x_start = start caculate_tokens = [] while x_start < end: for token in x_tokens: if token.tokenType == TokenType.T: caculate_tokens.append(Token(TokenType.CONST_ID, str(x_start), x_start)) else: caculate_tokens.append(token) x.append(get_float(caculate_tokens)) caculate_tokens = [] x_start += step
# 然后计算y的各种值 y_start = start caculate_tokens = [] while y_start < end: for token in y_tokens: if token.tokenType == TokenType.T: caculate_tokens.append(Token(TokenType.CONST_ID, str(y_start), y_start)) else: caculate_tokens.append(token) y.append(get_float(caculate_tokens)) caculate_tokens = [] y_start += step
ORIGIn IS (300+25*(1+1), 220); rot is0; scale is (50, 100); FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(T),sin(T)); scale is (100, 100); FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(2*T),sin(T));
输出结果:
测试二
测试数据:
1 2 3 4
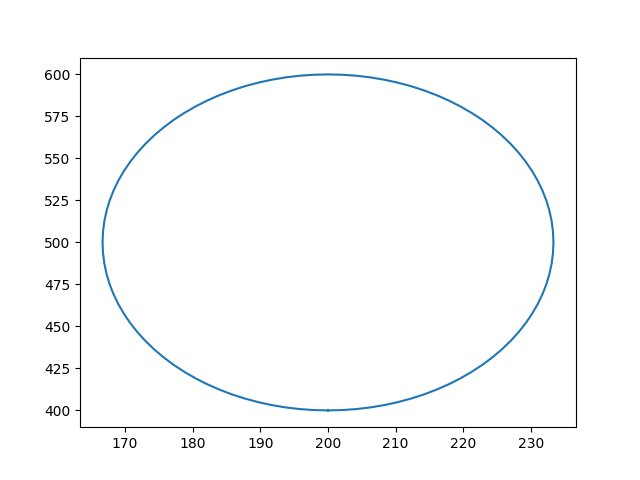
ORIGIN IS (200, 500); SCALE IS (100, 100/3); ROT IS PI/2; FOR T FROM 0 TO 2*PI STEP PI/50 DRAW (cos(T), sin(T));